In the classic model of information retrieval ([Salton & McGill 1983]; [Belkin & Croft 1992]), the func- tion of a document indexing engine is: the extraction of relevant items from the collection of text; the translation of such items into words belonging to the so-called Indexing Language ([Salton & McGill 1983]); and the arrangement of these words into data structures that support efficient search and retrieval capabilities. Similarly, the function of a search engine is: the translation of queries into words from the Indexing Language; the comparison of such words with the representations of the documents in the Indexing Language; and the evaluation and presentation of the results to the user.
The heterogeneous nature of the bibliographic data entered into our database (DATA), and the need to effectively deal with the imprecision in them led us to design a system where a large set of discipline-specific interpretations are made. For instance, to cope with the different use of abstract keywords by the publishers, and to correct possible spelling errors in the text, sets of words have been grouped together as synonyms for the purpose of searching the databases. Also, many astronomical object names cited in the literature are translated in a uniform fashion when indexing and searching the database to improve recall and accuracy.
In order to achieve a high level of software portability and database independence, the decision was made to write general-purpose indexing and searching engines and incorporate discipline-specific knowledge in a set of configuration and ancillary files external to the software itself. For instance, the determination of what parsing algorithm or program should be used to extract tokens indexed in a particular bibliographic field was left as a configurable option to the indexing procedure. This allowed us, among other things, to reuse the same code for parsing text both at search and index time, guaranteeing consistency of results.
The remainder of this section describes the design and implementation of the document indexing system used by the ADS: Sect. 3.1 provides an overview of indexing procedures; Sect. 3.2 details the organization of the knowledge base used during indexing; Sect. 3.3 discusses the implementation of the indexing engine. Details on the search engine and user interface can be found in SEARCH.
The model we followed for providing search capabilities to the ADS bibliographic databases makes use of data structures commonly referred to as inverted files or inverted indices ([Knuth 1973]; [Frakes & Baeza-Yates] 1992). To allow the implementation of fielded queries, an inverted file structure is created for each searchable field, as described in Sect. 3.3. (In the following we will refer to "bibliographic fields'' as the elements composing a bibliographic record described in the previous section -- e.g. authors, affiliations, abstract -- and "search fields'' as all the possible searchable entities implemented in the query interface and described in detail in SEARCH -- e.g. author, exact author, and text). In general the mapping between search fields and index files is one-to-one, while the mapping between inverted files and bibliographic fields is one-to-many. For instance, in our current implementation, the "author'' index consists of the tokens extracted from the authors field, while the "text'' index is created by joining the contents of the following fields: abstract, title, keywords, comments, and objects. The complete mapping between bibliographic fields and search fields is described in Sect. 3.3.
During the creation of the inverted files, the indexing engine makes use of several techniques commonly used in Natural Language Processing ([Efthimiadis 1996]) to improve retrieval accuracy and to implement sophisticated search options. These transformations provide the mapping between the input data and the words belonging to the Index Language. Some of them are described below.
Normalization: This procedure converts different morphological variants of a term into a single format. The aim of normalization is to reduce redundancy in the input data and to standardize the format of some particular expressions. This step is particularly important when treating data from heterogeneous sources which may contain textual representations of mathematical expressions, chemical formulae, astronomical object names, compound words, etc. A description of how this is implemented via morphological translation rules is provided in Sect. 3.2.1.
Tokenization: This procedure takes an input character string and returns an array of elements considered words belonging to the Indexing Language. While the tokenization of well-structured fields such as author or object names is straightforward, parsing and tokenizing portions of free-text data is not a trivial matter. For instance, the decision on how to split into individual tokens expressions such as "non-N.A.S.A.'' or designations for an astronomical object such as "PSR 1913+16'' is often both discipline and context-specific. To ensure consistency of the search interface and index files, the same software used to scan text words at search time is used to parse the bibliographic records at indexing time. A detailed description of the text tokenizer is presented in SEARCH.
Case folding: Converting the case of words during indexing is a standard procedure in the creation of indices and allows the reduction in size of most index files by removing redundancy in the input data. For example, converting all text to uppercase both at indexing and search time allows us to map the strings "SuperNova,'' "Supernova,'' and "supernova'' to the canonical uppercase form "SUPERNOVA.'' In our implementation the feature of folding case has been set as an option which can be selected on a field-by-field basis, since case is significant in some rare but important circumstances (e.g. the list of planetary objects). Details on the treatment of case in fielded queries are discussed in SEARCH.
Stop words removal: The process of eliminating high-frequency function words commonly used in the literature also contributes to reduce the amount of non-discriminating information that is parsed and indexed ([Salton & McGill 1983]). The use of case-sensitive stop words (described in Sect. 3.2.3) allows us to keep those words in which case alone can discriminate the semantics of the expression.
Synonym expansion: By grouping words in synonym classes we can implement a so-called "query expansion'' by returning not only the documents containing one particular search item, but also the ones containing any of its synonyms. Using a well-defined set of synonyms rather than relying on grouping words by stemming algorithms to perform query expansion provides much greater control in the implementation of query expansion and can yield a much greater level of accuracy in the results. This powerful feature of the ADS indexing and search engines is described more fully in Sect. 3.2.2.
The operation of the indexing engine is driven by a set of ancillary files representing a knowledge base ([Hayes-Roth et al. 1983]) which is specific to the domain of the data being indexed. This means that in general different ancillary files are used when indexing data in the different databases, although in practice much of the metadata used is shared among them.
Since the input bibliographies consist of a collection of fielded entries and each field contains terms with distinct and well-defined syntax and semantics, the processing applied to each field has to be tailored to its contents. The following subsections describe the different components of the knowledge base in use.
Morphological translation rules are syntactic operations designed to convert different representations of the same basic literal expression into a common format ([Salton & McGill 1983]). This is most commonly done with astronomical object names (e.g. "M 31'' vs. "M31''), as well as some composite words (e.g. "X RAY'', "X-RAY'' and "XRAY''). The translations are specified as pairs of antecedent and consequent patterns, and are applied in a case-insensitive way both at indexing and searching time. The antecedent of the translation is usually a POSIX ([IEEE 1995]) regular expression, which should be matched against the input data being indexed or searched. The consequent is an expression that replaces the antecedent if a match occurs, and which may contain back-references to substrings matched by the antecedent.
The table of translation rules used by the indexing and search engine uses two sets of replacement expressions for maximum flexibility in the specification of the translations, one to be used during indexing and the other one for searching. This allows for instance the contraction of two words into a single expression while still allowing indexing of the two separate words. For example, the expression "Be stars'' is translated into "Bestars'' when searching and "Bestars stars'' when indexing, so that a search for "stars'' would still find the record containing this expression. Note that if we had not used the translation rule described above to create the compound word "Bestars,'' the word "Be'' would have been removed since it is a stop word, and the search would have just returned all documents containing "stars.'' The complete list of translation rules currently in use is displayed in Table 1.
| Nr. | Input Pattern | Search replacement | Index replacement |
| 1. |
|
|
|
| 2. |
|
H
|
H
|
| 3. |
|
INFRARED
|
INFRARED
|
| 4. |
|
REDSHIFT
|
RED REDSHIFT
|
| 5. |
|
TTAURI | TTAURI TAURI |
| 6. |
|
XRAY
|
XRAY
|
| 7. |
|
GAMMARAY
|
GAMMA GAMMARAY
|
| 8. |
|
M
|
MESSIER
|
| 9. |
|
A
|
ABELL
|
| 10. |
|
NGC
|
NGC
|
| 11. |
|
|
|
| 12. |
|
|
|
| 13. |
|
SL
|
SHOEMAKER LEVY
|
| 14. |
|
SUNYAEV-ZELDOVICH | SUNYAEV-ZELDOVICH |
| 15. |
|
1987A | 1987A |
| 16. | ([A-Z])'S
|
|
|
| 17. |
|
|
|
| 18. |
|
|
|
| 19. |
|
|
|
| 20. |
|
|
|
| 21. | ([A-Z0-9]+)([
|
N/A |
|
| 22. | ([A-Z0-9]*[A-Z])([
|
N/A |
|
| 23. | ([A-Z0-9]*[0-9])([
|
N/A |
|
To avoid the performance penalties associated with matching large amounts of literal data against the translation rules, the regular expressions are "compiled'' into resident RAM when the ADS services are started, making the application of regular expressions to the input stream very efficient (SEARCH).
Despite the extensive use of synonyms in our databases, there are cases in which the words in an input query cannot be found in the field-specific inverted files. In order to provide additional search functionality, two options have been implemented in the ADS databases, one aimed at improving matching of English text and a second one aimed at matching of author names.
During the creation of the text and title indices, all words found in the database are truncated to their stem according to the Porter stemmer algorithm ([Harman 1991]). Those stems that do not already appear in the text and title index are added to the index files and point to the list of terms that generated the stem. Upon searching the database and not finding a match, the search engine proceeds to apply the same stemming rules to the input term(s) and then repeat the search. Thus word stemming is used as a "last-resort'' measure in an attempt to match the input query to a group of words that may be related to it. For searches that require an exact match, no stemming of the input query takes place. The limited use of stemming techniques during indexing and searching text in the ADS system derives from the observation that these algorithms only allow minor improvements in the selection and ranking of search results ([Harman 1991]; [Xu & Croft 1993]).
To aid in searches on author names, the option to match words which are phonetically similar was added in 1996 and is currently available through one of the ADS user interfaces. In this case, a secondary inverted file consisting of the different phonetic representations of author last names allows a user to generate lists of last names that can be used to query the database. Two phonetic retrieval algorithms have been implemented, based on the "soundex'' ([Gadd 1988]) and "phonix'' ([Gadd 1990]) algorithms.
A variety of techniques have been used in information retrieval to increase recall by retrieving documents containing not only the words specified in the query but also their synonyms ([Efthimiadis 1996]). By grouping individual words appearing in a bibliographic database into sets of synonyms, it becomes possible to use this information either at indexing or searching time to perform a so-called "synonym expansion''.
Typically, this procedure has been used as an alternative to text stemming techniques to automatically search for different forms of a word (singular vs. plural, name vs. adjective, differences in spelling and typographical errors). However, since the specification of the synonyms is database- and field-specific, our paradigm has allowed us to easily extend the use of synonyms to other search fields such as authors and planetary objects (SEARCH). Additionally, during the creation of the text synonym groups we were able to incorporate discipline-specific knowledge which would otherwise be missed. In this sense, the use of synonym expansion in ADS adds a layer of semantic information that can be used to improve search results. For instance, the following list of words are listed as being synonyms within the ADS:
circumquasar miniquasar nonquasar protoquasars qso qsos qsr qsrs qsrss qss quarsars quasar quasare quasaren quasargalaxie quasargalaxien quasarhaufung quasarlike quasarpaar quasars quasers quasistellar
During indexing and searching, by default any words which are part of the same synonym group are considered to be "equivalent'' for the purpose of finding matching documents. Therefore a title search for "quasar'' will also return papers which contained the word "quasistellar'' in their title. Of course, our user interface allows the user to disable synonym expansion on a field-by-field as well as on a word-by-word basis.
It is the extensive work that has gone into compiling such a list that makes searches in the ADS so powerful. To give an idea of the magnitude of the task, it should suffice to say that currently the synonyms database consists of over 55 000 words grouped into 9 266 sets. Over the years, the clustering of terms in synonym groups has incorporated data from different sources, including the Multi-Lingual supplement to the Astronomy Thesaurus ([Shobbrook 1995]).
Despite the fact that the implementation of query expansion through the use of synonyms illustrated above has shown to be an effective tool in searching and ranking of results, we are currently in the process of reviewing the contents and format of the synonym database to improve its functionality. First of all, as we have added more and more bibliographic references from historical and foreign sources, the amount of non-English words in our database has been slowly but steadily increasing. As a result, we intend to merge the proper foreign language words with each group of English synonyms in a systematic fashion ([Oard & Diekema 1997]; [Grefenstette 1998]).
Secondly, we intend to review and correct the current foreign words in our synonym classes to include, where appropriate, their proper representation according to the Unicode standard ([Unicode Consortium 1996]), which provides the foundation for internationalization and localization of textual data. By identifying entries in our synonym file that were created by transliterating words that require an expanded character set into ASCII, we can simply add the Unicode representation of the word to the synonym group, therefore ensuring that both forms will be properly indexed and found when either form is used in a search.
Finally, we are implementing a more flexible group structure for the synonyms which allows us to specify hierarchical groupings and relationship among groups rather than simple equivalence among words. This last feature allows us to effectively implement the use of a limited thesaurus for search purposes ([Miller 1997]). Instead of simply grouping words together in a flat structure as detailed above, we first create separate groups of words, each representing a distinct and well-defined concept. Words representing the concept are then assigned to one such groups and are considered "equivalent'' instantiations of the concept. A word can only belong to one group but groups can contain subgroups, representing instances of "sub-concepts''. The following XML fragment shows how grouping of synonyms is being implemented under this new paradigm:
<syngroup id="00751"> <subgroup rel="instanceof">00752</subgroup> <subgroup rel="instanceof">00753</subgroup> <subgroup rel="instanceof">00754</subgroup> <subgroup rel="instanceof">00755</subgroup> <subgroup rel="oppositeof">00756</subgroup> <syn>qso</syn> <syn>qsos</syn> ... <syn>quasistellar</syn> <syn lang="de">quasare</syn> <syn lang="de">quasaren</syn> <syn lang="de">quasargalaxie</syn> <syn lang="de">quasargalaxien</syn> </syngroup> <syngroup id="00752"> <syn>circumquasar</syn> <syn>circumquasars</syn> </syngroup> <syngroup id="00753"> <syn>miniquasar</syn> <syn>miniquasars</syn> <syn>microquasar</syn> <syn>microquasars</syn> </syngroup> <syngroup id="00754"> <syn>protoquasar</syn> <syn>protoquasars</syn> </syngroup> <syngroup id="00755"> <syn>quasar cluster</syn> <syn>quasar clusters</syn> <syn lang="de">quasarhäufung</syn> <syn lang="de">quasarhäufungen</syn> </syngroup> <syngroup id="00756"> <syn>nonquasar</syn> <syn>nonquasars</syn> </syngroup> <syngroup id="01033"> ... <subgroup rel="instanceof">00755</subgroup> ... <syn>cluster</syn> <syn lang="de">häufung</syn> ... </syngroup>
The new approach allows a much more sophisticated implementation of query expansion through the use of synonyms. Some of its advantages are:
1) Hierarchical subgrouping of synonyms: every group may contain one or more subgroups representing "sub-concepts'' related to the group in question. Currently the two relations we make use of are the ones representing instantiation and opposition. This capability allow us to break down a particular concept at any level of detail, grouping synonyms at each level and then "including'' subgroups as appropriate.
2) Multiple group membership: each subgroup may be an instance of one or more synonym groups. For instance, the synonyms "quasarhäufung'' and "quasar cluster'' are in a subgroup that belongs to both the "qso'' and the "cluster'' groups.
3) Use of multi-word sequences in synonym groups: in certain cases, individual words referring to a concept correspond to a sequence of several words in other languages or context. Allowing declarations of multi-word synonyms enables us to correctly identify most terms.
4) Multilingual grouping: words belonging to a language other than English are tagged with the standard international identifier for that language. This permits us to use the synonyms in a context sensitive way, so that if the same word were to exist in two languages with different meanings, the proper synonym group would be used when reading documents in each language.
The synonym database described above is used at indexing time to create common lists of document identifiers for words belonging to the same synonym group or any of its subgroups. The effect of this procedure is that when use of synonyms is enabled, searches specifying a word that belongs to a synonym group will result in the list of records containing that word as well as any other word in the synonym group or its subgroups. In the example given above, a search for "qso'' would have listed all documents containing "qso,'' its other synonyms, as well as subgroup members such as "miniquasar'' and "protoquasar.'' On the other hand, a search for "miniquasar'' would have only returned the list of documents containing either "miniquasar'' or "microquasar,'' narrowing significantly the search results.
A number of words considered "irrelevant'' with respect to the searches of the particular field and database at hand are ignored during indexing and searching. These words (commonly referred to as "stop words'') consist primarily of terms used in the English language with great frequency, as well as adverbs, prepositions and any other words not carrying a significant meaning when used in the context under consideration ([Salton & McGill 1983]). Such words are removed both at indexing and searching time, decreasing the number of irrelevant searches and disregarding search terms that would not yield significant results.
The use of both case-sensitive and case-insensitive stop words during indexing allows us to single out those instances of terms that may have different meanings depending on their case. For instance, the words "he'' and "He'' usually represent different concepts in the scientific literature (the second one being the symbol for the element Helium). By selectively eliminating all instances of "he,'' when indexing the bibliographies, we stand a good chance that the remaining instances of the word refer to the element Helium.
The effort currently underway to create a structured synonym database will be used to group and maintain the list of stop words in use. By simply clustering stop words in synonym groups and properly tagging the group as containing stop words, we can use the same software that is currently being developed to create and maintain the list of synonyms in our database. An example of the resulting records is shown below:
<syngroup id="00037" type="stop"> <!-- he is used in case-sensitive way to avoid removing "He" (element helium) from index --> <syn case="mixed">he</syn> <syn>she</syn> <syn lang="de">er</syn> <syn lang="de">sie</syn> <syn lang="fr">il</syn> <syn lang="fr">elle</syn> <syn lang="es">él</syn> <!-- as above, but without proper accenting --> <syn lang="es">el</syn> <syn lang="es">ella</syn> <syn lang="it">lui</syn> <syn lang="it">lei</syn> </syngroup>
This paradigm allows us to treat stop words as a special case of synonyms (which are identified by the indexing and search engines as being of type "stop'').
General-purpose indexing engines and relational databases were used as part of the abstract service in its first implementation ([Kurtz et al. 1993]), but they were eventually dropped in favor of a custom system as the desire for better performance and additional features grew with time ([Accomazzi et al. 1995]), as is often necessary in the creation of discipline-specific information retrieval systems ([van Rijsbergen 1979]). The approach used to implement the data indexing portion of the database can be considered "data-driven'' in the sense that parsing, matching and processing of input text data is controlled by a single configuration file (described below) and by the discipline-specific files described in Sect. 3.2.
The inverted files used by the search engine are the product of a pipeline of data processing steps that has evolved with time. To allow maximum flexibility in the definition of the different processing steps, we have found it useful to break down the indexing procedure into a sequence of smaller and simpler tasks that are general enough to be used for the creation of all the files required by the search engine. A key design element which has helped generalize the indexing process is the use of a configuration file which describes all the field-specific processing necessary to create the index files. The configuration file currently in use is displayed in Table 2. For each search field listed in the table, an inverted file structure is created by the indexing engine.
| Search Field | Bibliographic Fields | Translation | Tokenizer | Stop words | Case folding | Synonyms |
| exact author | <AUTHORS> | no | get_children | no | yes | no |
| title | <TITLE> | yes | text_parser | yes | yes | yes |
| text | <TITLE>, <ABSTRACT>, | yes | text_parser | yes | yes | yes |
| <KEYWORDS>, <OBJECTS>, | ||||||
| <COMMENTS> | ||||||
| keyword | <KEYWORDS> | no | get_children | no | yes | no |
| object | <OBJECTS> | yes | get_children | no | no | yes |
| author | (exact author occurrence table) | no | parse_authors | no | yes | yes |
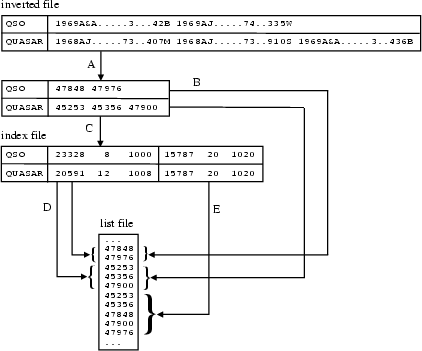
The first step performed by the indexing software is the creation of a list containing the document identifiers to be indexed. This usually consists of the entire set of documents included in a particular database but may be specified as a subset of it if necessary (for instance when creating an update to the index, see Sect. 3.3.3). The list of document identifiers is then given as input to an "indexer'' program, which proceeds to create, for each search field, an inverted file containing the tokens extracted from the input documents and the document identifiers (bibcodes) where such words occur. (In the following discussion we will refer to the tokens extracted by the indexer simply as "words,'' although they may not be actual words in the common sense of the term. For instance, during the creation of the author index, the "words'' being indexed are author names.) After all the inverted files have been created, each one of them is processed by a second procedure which generates two separate files used by the search engine: an "index'' file, containing the list of words along with pointers to a list of document identifiers, and a "list'' file, containing compact representations of the lists of document identifiers corresponding to each word.
The following subsections describe the procedures used during the different indexing steps: Sect. 3.3.1 details the creation of the inverted files; Sect. 3.3.2 describes the creation of the index and list files; Sect. 3.3.3 describes the procedures used to update the index and list files; Sect. 3.3.4 discusses some of the advantages and shortfalls of the implemented indexing scheme.
An inverted file ([van Rijsbergen 1979]; Frakes & Baeza-Yates 1992) is a table consisting of two columns: the first column contains the instances of words belonging to the indexing language, and the second column contains the list of document identifiers in which those words were found. The transformation of a document into its indexing language is performed in the following steps:
1) parsing of the document contents and extraction of all the bibliographic elements needed for the creation of one or more search fields; 2) joining of bibliographic elements that should be indexed together to produce a list of strings; 3) application of translation rules (if any) to the list of strings; 4) itemization of the list of strings into an array of words to be indexed; 5) removal of stop words from the list of words to be indexed (either case sensitively or insensitively); 6) folding of case for each of the words (if requested); 7) creation or addition of an entry for each word in a hash table correlating the word indexed with the document identifiers where it appears.
The indexer keeps a separate inverted file for each set of indexing fields to be created (see Table 2, Col. 1). Each inverted file is simply implemented as a sorted ASCII table, with tab separated columns. Given the current size of our databases, the creation of these tables takes place incrementally. A pre-set number of documents is read and processed by the indexer, an occurrence hash table for these documents is computed in memory, and an ASCII dump of the hash is then written to disk file as a set of keys (the words being indexed) followed by a list of document identifiers containing such words. The global inverted file is then created by simply joining the partial inverted files using a variation of the standard UNIX join command.
Once the occurrence tables for the primary search fields listed in Table 2 have been created, a set of derived fields are computed if necessary. Currently this step is used to create the "authors'' occurrence table from the "exact authors'' one by parsing and formatting entries in it so that all names are reduced to the forms "Lastname, F'' (where "F'' stands for the first name initial) and "Lastname.'' This allows efficient searching for the standard author citation format.
After all the primary and derived inverted files have been generated, a separate program is used to produce for each table two separate files which are used by the search engine: an inverted index file (here simply called "index'' file) and a document list file ("list'' file, see [Salton 1989]). The index file is an ASCII table which contains the complete list of words appearing in the inverted file and two sets of numerical values associated with it, the first set is used for exact word searches, the second one for synonym searches. The list file is a binary file containing blocks of document identifiers in which a particular word was found. Each set of numerical values specified in the index file consists of: the relative "weight'' of the word (or group of synonyms) in the database, as defined below; the length of the group of document identifiers in the list file, in bytes; the position of the group of document identifiers in the list file, defined as the byte offset from the beginning of the list file.
The value chosen to express the weight W(w) of a word w is a variation of the inverse document frequency ([Salton & Buckley 1988]):
where K is a constant, N is the total number of documents in the database, and df(w) is the document frequency of the word w, i.e. the number of documents in which the word appears ([Salton & Buckley 1988]). The choice of a suitable value for the constant K (currently set to K = 104) allows the indexing and search engine to perform most of the operations in integer arithmetic. To avoid performing slow log computations during the creation of the index files, the function that maps df(w) to W(w) is cached in an associative array so that when repeated integer values of df(w) are encountered, the pre-computed values are used.
The document identifiers which are stored in the list files are 32-bit integers (from here on called sequential identifiers) corresponding to line numbers in the list of bibliographic codes which have been indexed. The search engine resolves all queries on index files by performing binary searches on the words appearing in the index file, then reading the corresponding list of sequential identifiers in the list files, combining results, and finally resolving the sequential identifiers in bibcodes (see Fig. 2).
The procedure for the creation of the index and list files reads the inverted file associated with each search field and performs the following steps:
1) read all entries from the list of document identifiers (bibcode list) and create a hash table associating each bibcode with its corresponding sequential identifier;
2) if synonym grouping is to be used for this field, read the synonym file for this field and create a hash table associating each entry in the synonym group with the word with the highest frequency in the group;
3) for each word in the inverted file translate the list of bibcodes associated with it into the corresponding list of integer line numbers, and mark word as being processed;
4) if word belongs to a group of synonyms, sequentially find and process all other words in the same group, marking them as processed, then iteratively process all words in any of the subgroups until nesting of subgroups is exhausted; if no synonyms are in use, the same procedure is used with the provision that the group of synonyms is considered to be composed only of the word itself;
5) join, sort and unique the lists of sequential identifiers for all the words in the current group of synonyms;
6) write to the list file the sorted list of sequential identifiers for each word in the group of synonyms, followed by the cumulative list of sequential identifiers for the entire group of synonyms;
7) for each word in the group of synonyms, write to the index file an entry containing the word itself and the two sets of numerical values (weight, length, and offset) for exact word and synonym searches.
Figure 3 illustrates the creation of entries for two words in the "text'' index and list file from the text inverted file.
The separation of the indexing activity into two separate parts offers different options when it comes to updating an index. New documents which are added to the database can be processed by the indexer and merged into the inverted file quickly, and a new set of index and list files can then be generated from it. Similarly, since the synonym grouping is performed after the creation of the inverted files, a change in the synonym database can be propagated to the files used by the search engine by recreating the index and list files, avoiding a complete re-indexing of the database.
Despite the steps that have been taken in optimizing the code used in the creation of the index and list files from the occurrence tables, this procedure still takes close to two hours to complete when run on the complete set of bibliographies in the astronomy database using the hardware and software at our disposal. In order to allow rapid and incremental updating of the index and list files, a separate scheme has been devised requiring only in-place modification of these files rather than their complete re-computation.
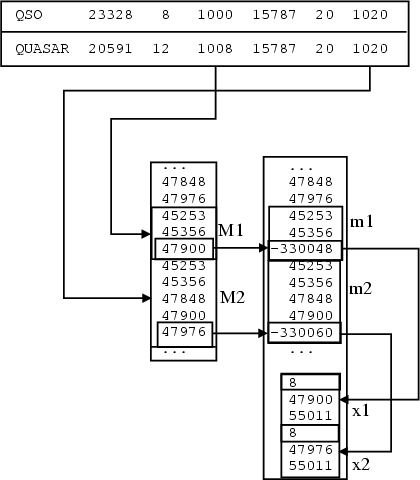
During a so-called "quick update'' of an operational set of index files used by the search engine, a new indexing procedure is run on the documents that have been added to the database since the last full indexing has taken place. The indexing procedure produces new sets of incremental index and list files as described above, with the obvious difference that these files only contain words that appear in the new bibliographic records added to the database. A separate procedure is then used to merge the new set of index and list files into the global index and list files used by the operational search engine, making the new records immediately available to the user. The procedure is implemented in the following steps (see Fig. 4):
1) Compute new sequential identifiers for the list of bibcodes in the incremental index by adding to each of them the number of entries in the operational bibcode list. This guarantees that the mapping between bibcodes and sequential identifiers is still unique after the new bibcodes have been merged into the operational index.
2) Append the list of sequential identifiers found in the incremental list file to the operational list file. In the case of identifiers corresponding to a new entry in the index file, their block of values is simply appended to the end of the operational list file. In the case of identifiers corresponding to an entry already present in the operational index file, the original list of identifiers ("main block'') needs to be merged with the new list of identifiers. In order to avoid clobbering existing data in the operational list file, the list of identifiers from the incremental index is appended to the end of the global list file, creating an extension of the main blocks of identifiers that we call an "extension block''. To accomplish the linking between main and extension blocks, the last sequential identifier in a main block is overwritten with a negative value representing the corresponding extension block's offset from the beginning of the list file (except the change in sign). An extension block contains as the first integer value the size of the extension block in bytes, followed by the last identifier read from the main block in the list file, followed by the sequential identifiers from the incremental index (see Fig. 4). When the search engine finds a negative number as the last document identifier value, it will seek to the specified offset, read a single integer entry corresponding to the number of bytes composing the extension block, and then proceed to read the specified number of identifiers. Note that because of the way extension blocks are created, the list of sequential identifiers created by concatenating the entries in the extension block to the entries in the main block is always sorted.
3) For each entry in each incremental index file, determine if a corresponding entry exists in the operational index file. If an entry is found, no modification of the index file is necessary, otherwise the index file is updated by inserting the entry in it. The values of the weights and offsets are corrected by taking into account the total number of documents in the operational index and the size of the list file.
One of the advantages of using separated index and list files is that the size of the files that are accessed most frequently by the search engine (the list of bibcodes and the index files) is kept small so that their contents can be loaded in random access memory and searched efficiently (SEARCH). For instance, the size of the text index file for the astronomy database is approximately 16 MB, and once the numerical entries are converted into binary representation when loaded in memory by the search engine, the actual amount of memory used is less than 10 MB.
The use of integer sequential identifiers in the list files allows more compact storage of the document identifiers as well as implementation of fast algorithms for merging search results (since all the operations are executed in 32-bit integer arithmetic rather than having to operate on 19-character strings). For instance, recent indexing of the ADS astronomy database produces text inverted files which have sizes approaching 500 MB, while the size of the text list file is about 140 MB.
The choice of a word weight which is a function of only the document frequency allows us to store word weights as part of the index files. It has been shown that a better measure for the relevance of a document with respect to a query word is obtained by taking into account both the document frequency df and the term frequency tf, defined as the frequency of the word in each document in which it appears ([Salton & Buckley 1988]), normalized to the total number of words in the document. The reasoning behind this is that a word occurring with high relative frequency in a document and not as frequently in the rest of the database is a good discriminant element for that document. Although we had originally envisioned incorporating document-specific weights in the list files to take into account the relative term frequency of each word, we found that little improvement was gained in document ranking. This is probably due to the fact that the collection of documents in our databases is rather homogeneous as far as document length and characteristics are concerned. Eventually the choice was made to adopt the simpler weighting scheme described above.
The procedures used to create the inverted files can scale well
with the size of the database since the global inverted file is
always created by joining together partial inverted files.
This allows us to limit the number of hash entries used by the indexer
program during the computation of the inverted files.
According to Heap's law ([Heap 1978]), and as verified experimentally
in our databases, a body of n words typically generates a vocabulary of
size
![]() where K is a constant and
where K is a constant and
![]() for English text ([Navarro 1998]).
Since the size of the vocabulary V corresponds to the number of
entries in a global hash table used by the indexing software, we see
that an ever-increasing amount of hardware resources would be
necessary to hold the vocabulary in memory; our choice of a partial
indexing scheme avoids this problem.
Furthermore, the incremental indexing model is quite suitable to
being used in a distributed computing environment where different
processors can be used in parallel to generate the partial inverted
files, as has been recently shown by [Kitajima et al. (1997)].
for English text ([Navarro 1998]).
Since the size of the vocabulary V corresponds to the number of
entries in a global hash table used by the indexing software, we see
that an ever-increasing amount of hardware resources would be
necessary to hold the vocabulary in memory; our choice of a partial
indexing scheme avoids this problem.
Furthermore, the incremental indexing model is quite suitable to
being used in a distributed computing environment where different
processors can be used in parallel to generate the partial inverted
files, as has been recently shown by [Kitajima et al. (1997)].
The procedures used to create the list and index files make use of memory sparingly, so that processing of entries from the occurrence tables is essentially sequential. The only exception to this is the handling of groups of synonyms. In that case, the data structures used to maintain the entries for the words in the current synonym group are kept in memory while the cumulative list of sequential identifiers for the entire group is built. The memory is released as soon as the entries for the current synonym group are written to the list and index files.
Copyright The European Southern Observatory (ESO)
![\begin{figure}\includegraphics[width=8cm]{DS1784F2.eps}\end{figure}](img10.gif)