All of the software development and data processing in the ADS has been carried out over the last 6 years in a UNIX environment. During the life of the project, the workgroup-class server used to host the ADS services has been upgraded twice to meet the increasing use of the system. The original dual processor Sun 4/690 used at the inception of the project was replaced by a SparcServer 1000E with two 85 MHz Supersparc CPU modules in 1995 and subsequently an Ultra Enterprise 450 with two 300 MHz Ultrasparc CPUs was purchased in 1997. These two last machines are still currently used to host the ADS article and abstract services, respectively.
Soon after after the inception of the article service in 1995 it became clear that for most ADS users the limiting factor when retrieving data from our computers was bandwidth rather than raw processing power. With the creation of the first mirror site hosted by the CDS in late 1996, users in different parts of the world started being able to select the most convenient database server when using the ADS services, making best use of bandwidth available to them. At the time of this writing, there are seven mirror sites located on four different continents, and more institutions have already expressed interest in hosting additional sites. The administration of the increasing number of mirror sites requires a scalable set of software tools which can be used by the ADS staff to replicate and update the ADS services both in an interactive and in an unsupervised fashion.
The cloning of our databases on remote sites has presented new challenges to the ADS project, imposing additional constraints on the organization and operation of our system. In order to make it possible to replicate a complex database system elsewhere, the database management system and the underlying data sets have to be independent of the local file structure, operating system, and hardware architecture. Additionally, networked services which rely on links with both internal and external web resources (possibly available on different mirror sites) need to be capable of deciding how the links should be created, giving users the option to review and modify the system's linking strategy. Finally, a reliable and efficient mechanism should be in place to allow unsupervised database updates, especially for those applications involving the publication of time-critical data.
In the next sections we describe the implementation of an efficient model for the replication of our databases to the ADS mirror sites. In Sect. 5.1 we describe how system independence has been achieved through the parameterization of site-specific variables and the use of portable software tools. In Sect. 5.2 we describe the approach we followed in abstracting the availability of network resources through the implementation of user-selectable preferences and the definition of site-specific default values. In Sect. 5.3 we describe in more detail the paradigm used to implement the synchronization of different parts of the ADS databases. We conclude with Sect. 5.4 where we discuss possible enhancements to the current design.
The database management software and the search engine used by the ADS bibliographic services have been written to be independent from system-specific attributes to provide maximum flexibility in the choice of hardware and software in use on different mirror sites. We are currently supporting the following hardware architectures: Sparc/Solaris, Alpha/Tru64 (formerly Digital Unix), IBM RS6000/AIX, and x86/Linux. Given the current trends in hardware and operating systems, we expect to standardize to GNU/Linux systems in the future.
Hardware independence was made possible by writing portable software that can be either compiled under a standard compiler and environment framework (e.g. the GNU programming tools, [Loukides & Oram 1996]) or interpreted by a standard language (e.g. PERL version 5, [Wall et al. 1996]). Under this scheme, the software used by the ADS mirrors is first compiled from a common source tree for the different hardware platforms on the main ADS server, and then the appropriate binary distributions are mirrored to the remote sites.
One aspect of our databases which is affected by the specific server hardware is the use of binary data in the list files, since binary integer representations depend on the native byte ordering supported by the hardware. With the introduction of a mirror site running Digital UNIX in the summer of 1999, we were faced with having to decide whether it was better to start maintaining two versions of the binary data files used in our indices or if the two integer implementations should be handled in software. While we have chosen to perform the integer conversion in software for the time being given the adequate speed of the hardware in use, we may revisit the issue if the number of mirror sites with different byte ordering increases with time.
Operating System independence is achieved by using a standard set of public domain tools abiding to well-defined POSIX standards ([IEEE 1995]). Any additional enhancements to the standard software tools provided by the local operating system is achieved by cloning more advanced software utilities (e.g. the GNU shell-utils package) and using them as necessary. Specific operating system settings which control kernel parameters are modified when appropriate to increase system performance and/or compatibility among different operating systems (e.g. the parameters controlling access to the system's shared memory). This is usually an operation that needs to be done only once when a new mirror site is configured.
File-system independence is made possible by organizing the data files for a specific database under a single directory tree, and creating configuration files with parameters pointing to the location of these top-level directories. Similarly, host name independence is achieved by storing the host names of ADS servers in a set of configuration files.
While the creation of the ADS mirror sites makes it virtually impossible for users to notice any difference when accessing the bibliographic databases on different sites, the network topology of a mirror site and its connectivity with the rest of the Internet play an important role in the way external resources are linked to and from the ADS services. With the proliferation of mirror sites for several networked services in the field of astronomy and electronic publishing, the capability to create hyperlinks to resources external to the ADS based on the individual user's network connectivity has become an important issue.
The strategy used to generate links to networked services external to the ADS which are available on more than one site follows a two-tiered approach. First, a "default'' mirror can be specified in a configuration file by the ADS administrator (see Fig. 6). The configuration file defines a set of parameters used to compose URLs for different classes of resources, lists all the possible values that these parameters may assume, and then defines a default value for each parameter. Since these configuration files are site-specific, the appropriate defaults can be chosen for each of the ADS mirror sites depending on their location. ADS users are then allowed to override these defaults by using the "Preference Settings'' system (SEARCH) to select any of the resources listed under a category as their default one. Their selection is stored in a site-specific user preference database which uses an HTTP cookie as an ID correlating users with their preferences (SEARCH).
In order to create links to external resources which are a function of a user's preferences, we store the parametrized version of their URLs in the property databases. The search engine expands the parameter when the resource is requested by a user according to the user's preferences. For instance, the parametrized URL for the electronic paper associated with the bibliographic entry 1997ApJ...486...42G can be expressed as $UCP$/cgi-bin/resolve?1997ApJ...486...42G. Assuming the user has selected the first entry in Fig. 6 as the default server for this resource, the search engine will expand the URL to the expression:
http://www.journals.uchicago.edu/cgi-bin/resolve?
1997ApJ...486...42G
This effectively allows us to implement simple name resolution for a
variety of resources that we link to.
While more sophisticated ways to create dynamic links have been
proposed and are being used by other institutions
([Van de Sompel & Hochstenbach 1999]; [Fernique et al. 1998]), there is currently no
reliable way to automatically choose the "best'' mirror site for a
particular user, since this depends on the connectivity between the
user and the external resource rather than the connectivity
between the the ADS mirror site and the resource.
By saving these settings in a user preference
database indexed on the user HTTP cookie ID (SEARCH),
users only need to define their preferences once and our interface
will retrieve and use the appropriate settings as necessary.
The software used to perform the actual mirroring of the databases consists of a main program running on the ADS master site initiating the mirroring procedure, and a number of scripts, run on the mirror sites, which perform the transfer of files and software necessary to update the database. The paradigm we adopted in creating the tools used to maintain the mirror sites in sync is based on a "push'' approach: updates are always started on the ADS main site. This allows mirroring to be easily controlled by the ADS administrator and enables us to implement event-triggered updating of the databases. The main mirroring program, which can be run either from the command line or through the Common Gateway Interface (CGI), is a script that initiates remote command procedures on the sites to be updated, sets up the environment by evaluating the mirror sites' and master site's configuration files, and then runs scripts on the remote sites that synchronize the local datasets with the ADS main site. The menu-driven CGI interface used for mirroring is shown in Fig. 7.
The updating procedures are specialized scripts which check and update different parts of the database and database management software (including the procedures themselves). For each component of the database that needs to be updated, synchronization takes place in two steps, namely the remote updating of files which have changed to a staging directory, and the action of making these new files operational. This separation of mirroring procedures has allowed us to enforce the proper checks on integrity and consistency of a data set before it is made operational.
The actual comparison and data transfer for each of the files to be updated is done by using a public domain implementation of the rsync algorithm ([Tridgell 1999a]). The advantages of using rsync to update data files rather than using more traditional data replication packages are summarized below.
1) Incremental updates: rsync updates individual files by scanning their contents, computing and comparing checksums on blocks of data within them, and copying across the network only those blocks that differ. Since during our updates only a small part of the data files actually changes, this has proven to be a great advantage. Recent implementations of the rsync algorithms also allow partial transfer of files, which we found useful when transferring the large index files used by the search engine. In case the network connection is lost or times out while a large file is transferred, the partial file is kept on the receiving side so that transfer of additional chunks of that file can continue where it left off on the next invocation of rsync.
2) Data integrity: rsync provides several options that can be used to decide whether a file needs updating without having to compare its contents byte by byte. The default behavior is to initiate a block by block comparison only if there is a difference in the basic file attributes (time stamp and file size). The program however can be forced to perform a file integrity check by also requesting a match on the 128-bit MD4 checksum for the files.
3) Data compression: rsync supports internal compression of the data stream sent between the master and mirror hosts by using the zlib library ([Deutsch & Gailly 1996]).
4) Encryption and authentication: rsync can be used in conjunction with the Secure Shell package ([Ylonen et al. 1999]) to enforce authentication between rsync client and server host and to transfer the data in an encrypted way for added security. Unfortunately, since all of the ADS mirror sites are outside of the U.S., transfer of encrypted data could not be performed at this time due to restrictions and regulations on the use of encryption technology.
5) Access control: the use of rsync allows the remote mirror sites to retrieve data from the master ADS site using the so-called anonymous rsync protocol. This allows the master site to exercise significant control over which hosts are allowed to access the rsync server, what datasets can be mirrored, and does not require remote shell access to the main ADS site, which has always been the source of great security problems.
During a typical weekly update of the ADS astronomy database, as many as 1% of the text files may be added or updated, while the index files are completely recreated. By checking the attributes of the individual files and transferring only the ones for which either timestamp or size has changed, the actual data which gets transferred when updating the collection of text files is of the order of 1.7% of the total file size (12 MB vs. 700 MB). By using the incremental update features of rsync when mirroring a new set of index files, the total amount of data being transferred is of the order of 38% (250 MB vs. 650 MB).
While the adoption of the rsync protocol has made it possible to dramatically decrease the time required to update a remote database, there are several areas where additional improvements could be made to the current scheme in an effort to reduce the amount of redundant processing and network transfers on the main ADS server. Some of the planned improvements are discussed below.
Given the CPU-intensive activity of computing lists of file signatures and checksums for files selected as potential targets for a transfer, the rsync server running on the main ADS site is often under a heavy load when the weekly updates of our bibliographic databases are simultaneously mirrored to the remote sites. Under the current implementation of the rsync server software, each request from a mirror site is handled by a separate process which creates the list of files and directories being checked. Therefore, the load on the server increases linearly with the number of remote hosts being updated, although much of the processing requested by the separate rsync connections is in common and takes place at the same time. By adding an option to cache the data signatures generated by the rsync server and exchanged with each client, most of the processing involved could be avoided. This option, first suggested by the author of the rsync package ([Tridgell 1999b]) but never implemented, would significantly benefit busy sites such as the ADS main host. A similar approach has been used by [Dempsey & Weiss (1999)] to implement an experimental replication mechanism based on rsync. We hope that a stable and general approach to this caching issue can be adopted soon and are collaborating with the maintainers of the package on its development.
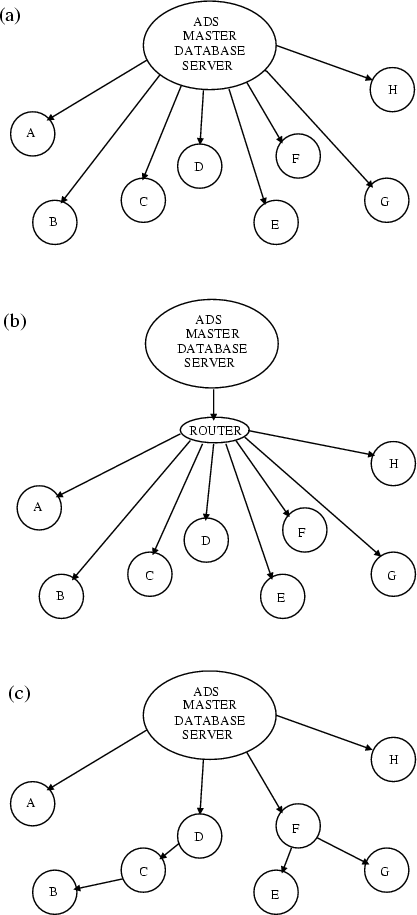
A second improvement that would significantly reduce the bandwidth currently used during remote updating of the ADS mirror sites is the implementation of a multicasting or cascading mirroring model (see Fig. 8). Internet multicasting is still a technology under development ([Miller et al. 1998]) and efficient implementations require special software support at the IP (Internet Protocol) level, over which we have no control. The cascading model can instead by implemented at the application level using current software tools. Under this model, the administrator of the main server to be cloned defines a tree in which the nodes represent the mirror sites, with the root of the tree being the main site. Data mirroring is then implemented by having each node in the tree "push'' data to its subordinate nodes. This approach trades off the simplicity of simultaneous updating for all mirror sites from a central host in favor of a sequence of cascading updates, which is a sensible solution once the number of mirror sites becomes large. We are currently experimenting with this model on a prototype system and plan to make the design operational if it proves to be advantageous.
Copyright The European Southern Observatory (ESO)
![\begin{figure}\includegraphics[width=9cm]{DS1784F6.eps}
\par\end{figure}](img18.gif)
![\begin{figure}\includegraphics[width=10cm]{DS1784F7.eps}
\par\end{figure}](img19.gif)